

Caro leitor, você sabe o que é malha de dados? Não? Então pare agora mesmo de ler este artigo, acesse o link abaixo, o qual vai te explicar o que é Arquitetura de Malha de Dados. Depois volte aqui, que estarei esperando.
Porém, se você já sabe o que é “Arquitetura de Malha de Dados”, então continue comigo, que vamos entender como projetar essa arquitetura.
Como vocês já sabem “Arquitetura de Malha de Dados” faz uma abordagem descentralizada dos dados, permitindo que Equipes de Domínio realizem análises de dados sem a necessidade de acionar a área de TI. No núcleo está o domínio onde tem uma equipe responsável e os seus dados operacionais e analíticos.
Abaixo tem uma visão de como é a Arquitetura de Malha de Dados.
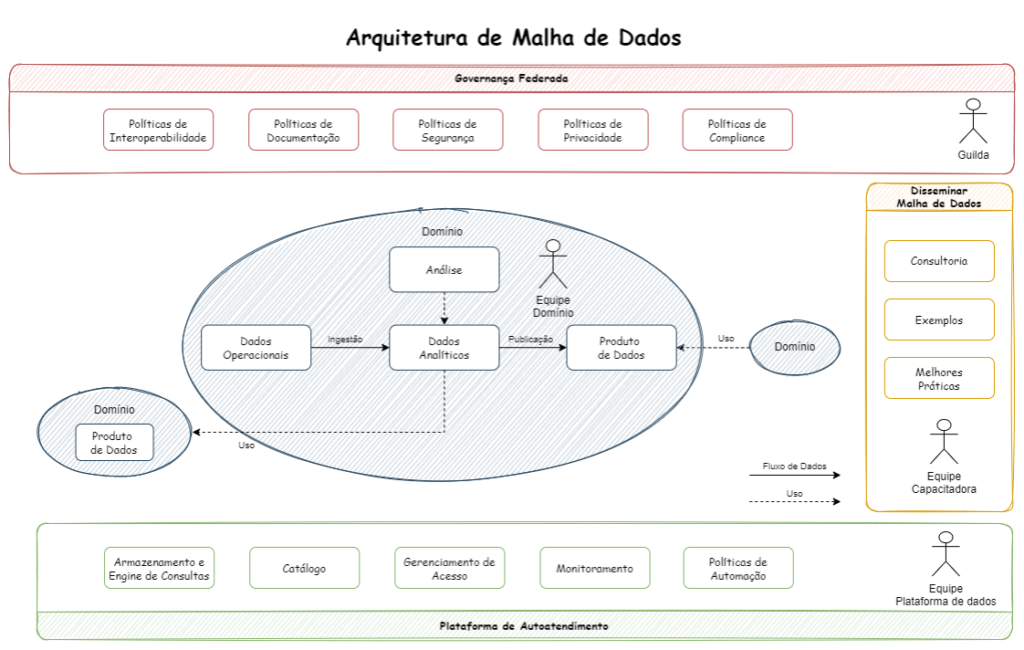
Para projetar e implantar a Arquitetura de Malha de Dados precisamos das seguintes equipes:
- Equipe de Domínio
- Equipe de Governança Federada
- Equipe Capacitadora
- Equipe da Plataforma de Dados
A equipe de domínio, como todos já devem saber pois leram o artigo anterior, é uma equipe que tem autonomia para tratar os dados do seu domínio.
A equipe de Governança Federada, tem um papel importantíssimo nessa arquitetura. É essa equipe que vai determinar os padrões de desenvolvimento, garantir que a documentação seja adequada, regras de interoperabilidade, etc.
A equipe Capacitadora fica responsável em difundir a Arquitetura de Malha de Dados, orientando as equipes de domínio sobre modelagem de dados analíticos, como usar a plataforma de dados e quais os padrões para criar e manter produtos de dados.
A equipe da plataforma de dados é responsável por manter a estrutura funcionando e permitir que tenha funções de autoatendimento.
Um outro ponto importante nessa arquitetura, é que a equipe de domínio deve concordar com as políticas da empresa, como interoperabilidade, segurança e padrões de documentação. Isso é necessário para que as equipes de domínio possam descobrir, entender e usar produtos de dados disponíveis na malha de dados.
Também é importante ter uma plataforma de autoatendimento fornecido pela equipe que cuida da plataforma de dados, onde é possível criar facilmente os produtos de dados e permitir fazer as análises com eficiência.
Lembram dos componentes principais da Arquitetura da Malha de Dados que foi explicado no artigo anterior? Não? Então para tudo, volta lá no artigo anterior, veja quais são os componentes principais e depois volte aqui que estarei esperando.
São esses os principais componentes da Arquitetura da Malha de Dados:
- Propriedade de domínio
- Produto de dados
- Plataforma de infraestrutura de dados de autoatendimento
- Governança Federada
Vamos acrescentar mais alguns itens esses componentes principais e ver como se relacionam.
Produto de dados
Um produto de dados geralmente é um conjunto de dados disponibilizado para ser acessado por outras equipes de domínio. É parecido com uma API ou um micro-serviço.
Por exemplo:
- O arquivo de Notas Fiscais geradas no dia anterior e disponível no Data Lake.
- Um arquivo no formato json diário com os pedidos de compra no Google BigQuery.
- Um relatório com a relação de contas a pagar baixadas no dia anterior disponíveis em um servidor da empresa.
- Um dashboard com a última posição resumida dos caminhões de uma empresa de logística.
Dá para perceber que os Produtos de Dados são infinitos. Podemos até ter KPIs.
E para que todos esses produtos sejam adequadamente utilizados é necessário ter uma boa documentação dos metadados, incluindo a propriedade (dono do produto), informações de contato, onde localizar, como acessar os dados, frequência de atualização e um modelo de dados do produto.
A equipe de domínio será sempre responsável pelo produto de dados durante o ciclo de vida. Ou seja, é necessário monitorar o produto e garantir a qualidade e disponibilidade dos dados. Por exemplo: Não ter dados nulos, ou ter letras onde somente deve existir números. Não ter duplicidades.
Governança Federada
As pessoas que compõem o time de Governança Federada, normalmente é organizada por representantes de todas as equipes que participam da malha dados.
Essas pessoas concordam com a políticas globais da empresa referente as regras de construção dos produtos de dados.
Um dos primeiros pontos a serem acordados são as políticas de interoperabilidade. Essas políticas irão permitir que outras equipes de domínio usem os produtos de dados de forma consistente. Por exemplo: a regras definem que a forma de fornecer os dados é através de um banco de dados. Ou através de arquivos CSV em local único para todos os produtos de dados.
O próximo passo é definir o formato da documentação que permita identificar e entender os produtos de dados disponíveis. Pode ser um arquivo .doc, uma página wiki, onde são predefinidas as informações importantes dos produtos de dados, tais como: metadados, proprietário do produto, periodicidade de atualização, etc.
A forma de acesso ao produto é outro item que precisa ter regras definidas. Por exemplo: Acessos a bancos de dados, acessos a pastas, acessos a um serviço em nuvem, etc.
E aqui também não podemos esquecer da LGPD. Neste item é descrito as políticas globais de privacidade e conformidade dos dados PII. Ou seja, sabemos o quanto é importante a proteção dos dados.
Para quem não sabe o que são dados PII segue um link para maiores detalhes: https://pt.wikipedia.org/wiki/Informa%C3%A7%C3%A3o_pessoalmente_identific%C3%A1vel
Dados analíticos
Para ter um produto de dados é claro que precisamos de dados operacionais. Sem isso dificilmente conseguiremos ter um produto de dados.
Neste item temos que ter claro qual é o fluxo de dados até chegar ao produto de dados.
Podem ser dados estruturados, semi estruturados e não estruturados. Vale ressaltar que os dados estão no seu estado bruto. Neste caso é necessário um pré-processamento, onde os dados brutos são tratados (limpos e estruturados) colocando-os em eventos e entidades.
Os eventos são orientados ao domínio e são imutáveis. Por exemplo: Pedido de Venda, Ordem de Pagamento, etc.
As entidades representam o negócio. Por exemplo: Vendas e Finanças. E seu estado muda ao longo do tempo. Nas entidades podemos representar fotos de um instantâneo, por exemplo, fechamento mensal.
Também podem haver dados importados manualmente. Por exemplo, um arquivo CSV, um email, etc.
E os dados de outros domínios que já vem estruturados? Esses são tratados como dados externos. Ao usar produtos de dados de outras equipes, que estão aderentes as políticas da governança federada, a integração é relativamente simples.
No final de todo esse processo, temos o produto de dados publicado, que pode ser uma agregação de várias informações, tais como, subconjuntos de eventos, entidades, dados manuais e dados externos.
Ingestão de Dados
A equipe de domínio tem total responsabilidade sobre a ingestão de dados dentro do seu domínio.
E como os dados operacionais podem ser ingeridos na plataforma de dados?
Para responder a essa pergunta existem duas opções: Processamento batch ou Processamento em Tempo Real. A equipe pode lançar mão das duas formas separadamente ou combinadas. Qual é a melhor opção? Ou talvez devêssemos perguntar: Qual a opção que resolve um problema do domínio? Portanto, dependendo da necessidade usa-se a opção que melhor atende.
Vamos exemplificar.
Processamento em Tempo Real:
Uma equipe de domínio, responsável por dados de uma Black Friday, precisa responder rapidamente uma questão inerente ao cenário: Faço ou não um ajuste de preço em um determinado produto? Para esse cenário é necessário ter o Processamento em Tempo Real para responder a essa questão. Os dados devem ser coletados, processados e encaminhados para a plataforma de dados em tempo real, ou no máximo em micro-batches. Essa forma de trabalhar também é conhecida como ingestão de streaming, onde os dados, quando chegam, são enviados em pequenos lotes, para então estarem imediatamente disponíveis para análise.
Para essa forma de processamento, os eventos de domínio são uma ótima opção, pois representam fatos comerciais relevantes. Isso funciona bem para esse tipo de processamento porque os eventos de domínio já estão bem definidos e há pouco a fazer em relação ao pré-processamento e limpeza.
Processamento batch:
É o tradicional ELT e ETL preparados para gerar informações agregadas em diversos níveis através do processamento batch. Também é ideal para avaliar a qualidade dos dados e verificar duplicações. Essa é a forma mais indicada para trabalhar com os sistemas legados.
Limpeza de Dados
Lembra do ditado: Se entra lixo, vai sair lixo.
É neste ponto que temos que avaliar com muito critério a qualidade dos dados.
Para uma análise de dados eficaz é necessário que os dados sejam eficientemente tratados e limpos. Em uma malha de dados, as equipes de domínio são responsáveis por essa tarefa. Como conhecem bem o seu domínio, podem identificar como os seus dados precisam ser processados. E caso for necessário, realizar transformações.
Em alguns cenários os dados podem ser inseridos na sua forma bruta, sem tratamento e não estruturados. E num momento seguinte são limpos, transformados e inseridos na plataforma de dados.
No momento da limpeza dos dados alguns passos são muito importantes. Veja abaixo:
Estruturação: Os dados não estruturados e semi estruturados devem ser transformados em dados estruturados. Por exemplo, estruturar as informações de um arquivo JSON.
Mitigar mudanças estruturais: Pode acontecer de uma estrutura de dados ser alterada na sua origem. Portanto é necessário se adequar a essas mudanças. Para isso podem ser adotadas regras de tratamento, como por exemplo, preencher campos nulos com um valor padrão sensato.
Eliminar duplicidade de registros: Em alguns casos pode ocorrer de ter valores duplicados. Portanto no processo de limpeza devem ser removidas as duplicidades.
Completude: É importante avaliar se os dados estão completos, por exemplo: contenham os períodos acordados, ou campos que não podem ser nulos.
Outliers: Dados fora do padrão, mais conhecidos como outliers, podem ocorrer por diversos motivos. Portanto devem ser tratados e corrigidos ou simplesmente eliminados.
Em um pipeline de dados, a limpeza pode ser realizada através de linguagem SQL, Linguagens de programação e até ferramentas de ETL.
Análise
Os dados foram processados, limpos e armazenados na estrutura de dados do domínio.
Agora vem a análise. É neste momento que as equipes de domínio consultam, processam e agregam seus dados analíticos em busca de insights. Em algumas situações utilizam também produtos de dados relevantes de outros domínios.
Na maioria dos casos, o SQL é utilizado para a tarefa de análise. Tem bastante flexibilidade e funções poderosas para conectar e investigar os dados.
A plataforma de dados deve permitir realizar a operações de seleção e junção de entidades com eficiência, mesmo em grandes conjuntos de dados.
Outra opção para realizar análises são os Notebooks. Ajudam a processar, explorar e documentar as descobertas.
Sabemos que as pessoas percebem as informações visualmente. Para isso lançamos mão das ferramentas de visualização de dados que criam excelentes gráficos, visões de KPIs, dashboards e relatórios. Existem excelentes ferramentas para construir visualizações e que permitem várias possibilidades de ações.
Ahh, mas você quer aplicar ciência de dados, aprendizado de máquina, redes neurais? Então é aqui que você entra para conseguir insights mais avançados. Aqui é possível vários tipos de ações, tais como, análises de correlação, modelos de previsão, modelos de classificação, processamento de linguagem natural e outros casos de uso avançados. É claro que para isso são necessárias algumas habilidades diferenciadas, tais como metodológicas, estatísticas e tecnológicas.
Plataforma de dados
A plataforma de dados pode variar para cada organização.
Os recursos disponíveis na plataforma de dados podem ser recursos analíticos ou recursos de produtos de dados.
Em recursos analíticos é possível criar modelos de dados analíticos e executar análise para decisões orientadas a dados. Para que isso seja viável, é necessário que a plataforma de dados tenha funções de ingerir, armazenar, consultar e visualizar dados através de autoatendimento. Soluções de Data Warehouse e Data Lake já permitem o autoatendimento. A principal diferença é que cada equipe de domínio tem sua própria área de recursos analíticos.
Uma plataforma de dados mais avançada com autoatendimento deve dar suporte às equipes de domínio para que possam criar rapidamente novos produtos de dados e executá-los em produção em sua própria área. E também deve apoiar a equipe de domínio na publicação de seus produtos de dados garantindo que outras equipes possam descobri-los.
E para que seja possível descobri-los é necessário ter um catálogo de dados (documentação) através de uma intranet wiki ou repositório git. Não precisa ficar limitado a essas duas opções. Cada empresa pode implementar o seu catálogo de produtos da forma que seja mais adequada.
A plataforma também deve oferecer suporte, monitorar e documentar o acesso entre domínios e o uso de produto de dados.
Uma plataforma de dados ainda mais avançada oferece suporte a aplicação e automação de políticas. Ou seja, a equipe de domínio não precisa se preocupar em garantir que as políticas globais não sejam violadas. A plataforma de dados se encarrega de implementar regras que garantam a não violação das políticas globais.
Por exemplo: Padronização dos metadados. Remoção automática de dados PII durante a ingestão dos dados.
Para que a plataforma de dados seja realmente um sucesso é importante que haja um mecanismo de consulta eficiente através de uma única linguagem de consulta aos dados.
Equipe capacitadora
A equipe capacitadora deve estar preparada e treinada para espalhar a ideia da malha de dados dentro da organização.
Quando a empresa decide iniciar a adoção da malha de dados, a equipe capacitadora será muito exigida para disseminar a ideia. Essa equipe também deve atuar como defensora da malha de dados. Também auxiliam as equipes de domínio a se tornarem membros ativos da malha de dados.
E quem são as pessoas que fazem parte da equipe capacitadora? Alguns perfis de profissionais mais indicados para essa equipe são: especialista em análise de dados, engenheiros de dados e especialistas em plataformas de autoatendimento.
Um membro da equipe capacitadora pode se juntar temporariamente a uma equipe de domínio por um período limitado como consultor. O objetivo é entender as necessidades da equipe de domínios e criar um ambiente de aprendizado, treinar os membros da equipe de domínio em análise de dados, além de orientá-los a como utilizar a plataforma de dados de autoatendimento.
Não é função da equipe capacitadora de criar produtos de dados.
Também compartilham materiais de aprendizado e recomendam as melhores práticas na utilização da malha de dados.
Conclusão
Tem muito trabalho envolvido para a implementação da Arquitetura de Malha de Dados.
Muitas pessoas serão envolvidas. Muitos profissionais especializados em dados deverão estar presente nessa construção.
Mas para que isso tenha aceitação plena é necessário que o alto escalão da empresa apoie e incentive a criação da Arquitetura da Malha de Dados.
Os benefícios são muitos, tais como, responder rapidamente às perguntas de negócio, menor tempo para implementar novas análises e produtos de dados e não ter que entrar na fila de desenvolvimento da equipe de TI.


